I have just uploaded my first paper to arXiv. The title is “Human Genome Variation and the concept of Genotype Networks“, and presents a first, preliminary application of the concept of Genotype Networks to human sequencing data. I know that the title may sound a bit pretentious, but we wanted to pay a tribute to a great article by John Maynard Smith, to which the work presented is inspired.
Nevertheless, in this blog post I am not going to discuss the contents of the paper, but only on how I did this work. This was a project that I did in my last year of my PhD, and I have made an extra effort in trying to follow every best practice rules I knew.
I started my PhD in the pre-bedtools and pre-vcftools era of bioinformatics, and I saw the evolution of this field, from a spare group of people in nodalpoint to the rise of Biostar and Seqanswers. During this time, I have read and followed a lot of discussions about “what is the best way to do bioinformatics”, from whether to use source control, to testing, and much more. For the last project as a PhD student, I wanted to apply all the practices that I had learn, to determine if it was really worth to spend time learning them.
Premise: dates and times of the project
My PhD fellowship supports a three months stay in another laboratory in Europe. I decided to do it in prof. Andreas Wagner’s group in Zurich.
The decision to go to Wagner’s group was motivated by a book that he had recently published, entitled “The Origins of Evolutionary Innovations”. Previous to the start of this project I had read some articles by Andreas Wagner, and found them very interesting, so the opportunity to stay in his lab was very exciting. However, in light of what I learned during this time, I have admit that before December 2011, I didn’t understand most of the concepts present in the book. Thus, we can say that for this project, I started from zero.
I started thinking of this project in December 2011. I did the first practical implementation in the three months of the stay in Zurich, from May to August 2012. The first preliminary results came in January 2013, and the first manuscript in April 2013. We submitted to ArXiv in August 2013. During this period of time, I have also worked on three other projects, wrote my thesis, and taught at the Programming for Evolutionary Biology workshop in Leipzig.

Note: this blog article is very long, you may want to download as PDF and read it more comfortably.
1. Preparing a book club on the topic
The first step has been to prepare a book club on the topic of the project. I have even posted the slides here in my blog:
Preparing the book club has been a good way to read a lot of literature on the topic, and to have a good overview on it. Thank to the book club, I was also able to identify which people in my institute were interested in the argument, and to get some preliminary feedback from them.
After three or four months doing the book club, I started having some ideas on what to do in the project. Actually, I got the main idea for the project when I was preparing some figures for the book club. Moreover, some of materials prepared for the slideshows was later very useful to write the proposal, to explain the project to other people, and to describe it in the thesis.
Take home message 1: read a lot of literature before starting a project. It will help you having good ideas, and to plan things well.
2. Planning
From my experience, I believe that most research project fail because they are poorly planned. At the beginning of my PhD, I wasted a lot of time working on projects that were not defined correctly. These project were very valid on the scientific level, but they were just not planned enough, and too many unclear details were unclear when I started them. So, for this project I wanted to dedicate a good amount of time to the planning, before starting writing any code.
The first project plan was in the form of a Trello table. You can see it by clicking on the following image:

The table that you can see there is actually not the first plan that I wrote, because over time I have modified and changed it. In any case, the structure has remained almost the same: one column for the Project Outline, one for the list of Tables and Figures in the paper, and one for the Questions to be Answered by this Project. There were also a few more columns dedicated to alternative hypothesis that I wanted to test, but I have archived them now.
After writing down this preliminary table, I prepared a slideshow, and asked to all the people who attended the book club to give me some feedback on it. It was a good discussion, which led to many improvements, which you can see resumed in the 4th column Bioevo Seminar March 2012. I did something similar a few days after arriving to Zurich (see the 5th column). After doing so, I have also wrote a text document resuming the whole project.
You may notice that the table contains other columns, related to the feedback I have received in some seminars and conferences. I will describe this later, in the section “Getting Feedback from others”.
Take home message 2: a simple way to create a project plan is to fill a table with three columns: Project Outline, Tables and Figures, and Questions to be Answered by this Project.
3. Keeping the code in a Versioned Repository
After the project plan was ready, it was the time to start coding. A good way to organize all the code related to a project is to keep everything in a repository, which in my case was a mercurial repository hosted on bitbucket. Click on the image to see the code:
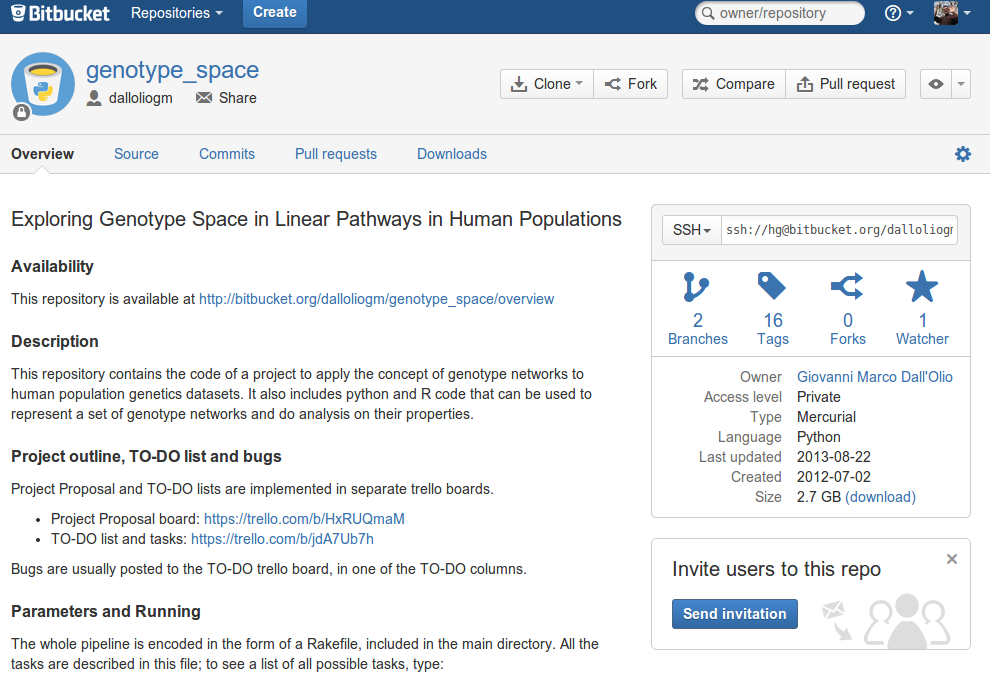
A brief introduction to the concept of repository and version control. Basically, I keep all my code into a main folder, and, thanks to a software called mercurial, I keep track of all the changes made to all the files within this folder. Mercurial also allows to copy the whole folder to different computers, and also in a remote server. In my case, I keep a copy of my repository in a free service called bitbucket, and other copies on each of my working computer. When you click on the image above, you access to the copy of my code hosted in bitbucket.
After one year and an half of work, I accumulated about 2400 commits for this project, meaning that I have saved the code or the results about 2400 times in total. In general, I save a commit every time I make a significant change to the code, every time I run tests, and every time there is a new input file or result. The following charts shows my activity over time:
 Since making this graph is a great fun, here is the punchcard of how much I worked per hour:
Since making this graph is a great fun, here is the punchcard of how much I worked per hour:

(it seems that I am specially productive on Wednesday at 3PM and on Thursday at 6 PM – I am not able to explain why :-). )
The most common criticism against version control is that you waste time writing the commits. If you have to interrupt your work every 30 minutes to write a note about what you have just done and why, then you go slower than other people who do not track changes. This is partially true, and I think that in some cases I have been too strict, and committed too often. However, over all I think that my experience with version control has been very good, and that the benefits are higher than the drawbacks.
– version control is great for synchronizing the code on multiple computers. The advantage of version control that I have enjoyed the most has been the ability to synchronize multiple copies of the code among different computers. I worked daily on three computers: my workstation, my laptop, and the cluster. Every time I switched to another computer, I was able to use mercurial to automatically synchronize the changes, and manage any eventual conflict. In some cases, I was maintaining a parallel version of the code in the cluster. Thanks to version control, this worked very smoothly, and I never had doubts or problems related to different versions being used.
– version control is also great for keeping a log of the changes. One of the first thing that I did in the morning was to check the history of changes, to help me remember what I was doing the day before (together with the scrum table described in the next section). The log of changes was also useful when I had to resume the work on a specific task, after having focused on another for a while.
– version control for tracking data and results files. In general, storing results files in a repository is considered to be a bad practice, but I was working alone, and nobody complained. It was really useful for me to track data and results files, because I was maintaining different copies synchronized among many computers. Of course, I did not track the huge result files (e.g. for the whole genome), or the raw data from 1000 Genomes.
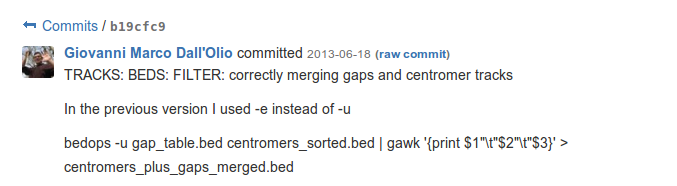
– version control for remembering which commands have been used to generate a result file. Over time, I developed the habit of saving the commands executed to save every version of a result file. For example, in this commit, I saved the command line and options used a certain bed file. In theory these commands should go to a Makefile or a Rakefile, but during the development these commands changed so frequently that it was easier to store them in the commit messages.
– version control is good to tag versions of the code specific to a conference or other events. If you look at the figure of the “activity” above, or browse the repository, you will see that there are some “labels” marking specific commits. For example, the “ECCB_poster” label marks the version of the code that I used to generate a poster for the ECCB conference, and the no_ASW marks a version in which I decided to remove all the ASW samples from the project. This is great for the reproducibility of my results.
Take Home Message 3: Version control is great to keep track of changes, and to manage multiple copies of the code.
4. Software Testing
A good practice is to write code tests, to check that your script are actually working as you intended them to be. My code has about 300 unit tests, ranging from the most silly, to the ones for which I had to do some manual calculations. If you click on the following screenshot, you will access the folder of tests in my repository:
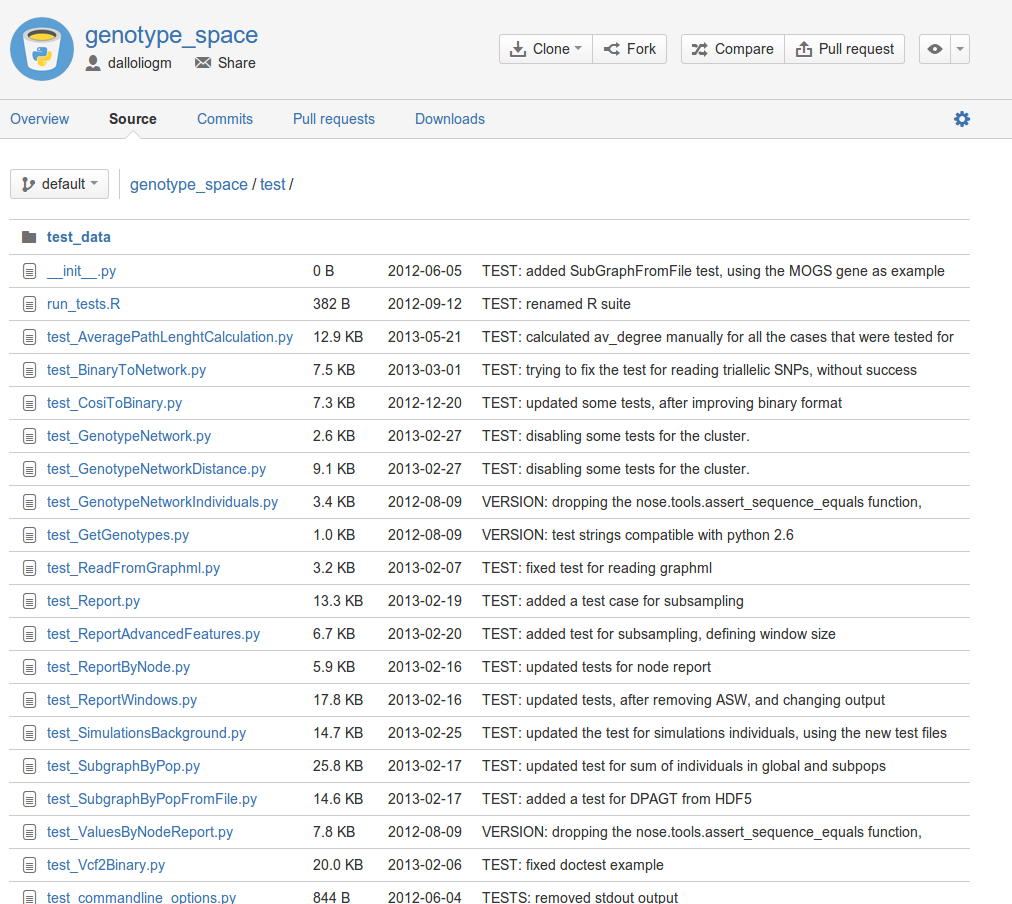
One great advantage of the tests is that they give you an incredible flexibility over the code. If your code is covered by tests, you have the freedom to modify or alter it without having to worry about getting a different result. In one case I switched to another version of a library, and thanks to testing I was able to identify all the consequences of this upgrade on the result. In many cases I rewrote completely one script or function, and thanks to the tests I didn’t have to worry about getting different results. Having your code covered by tests makes you very powerful on it.
The tests I wrote can be roughly classified into three groups:
– simple copy&paste of the output. Some tests are just the copy&paste of the output of a script. For example, I have a script that reads a VCF file and prints some statistics on the screen. The test in this case is just the output of the script on my computer.

These tests are easy to produce, and they are very useful, because they allow to check if the output of the script is the same on any computer and configuration. Sometimes, this is not true, and these “copy&paste” scripts are the only way to know it. For example, in some cases one of my scripts had a different behaviour in my laptop, compared to my workstation and the cluster. This was due to a different version of a library – and without a test, I would never have noticed the difference. Click here for an example of test written in this way.
This class of tests is also useful when you make large changes to the code. For example, at a certain point I switched from the igraph 0.5.4 library, to the 0.6. These two versions are not compatible, and they require many changes in the code to produce the same output. Thanks to the tests, I was able to quickly upgrade to the new library, and make the changes needed to get the same output as before.
– tests produced by manually calculating the expected output of a script. The purpose of my project was to calculate certain Network Theory properties from a specific representation of a VCF file. Thus, I had to make sure that my code calculated correctly these network properties, e. g. if the node degree and the network diameter were correct, and if the data filtering steps worked as they were expected.
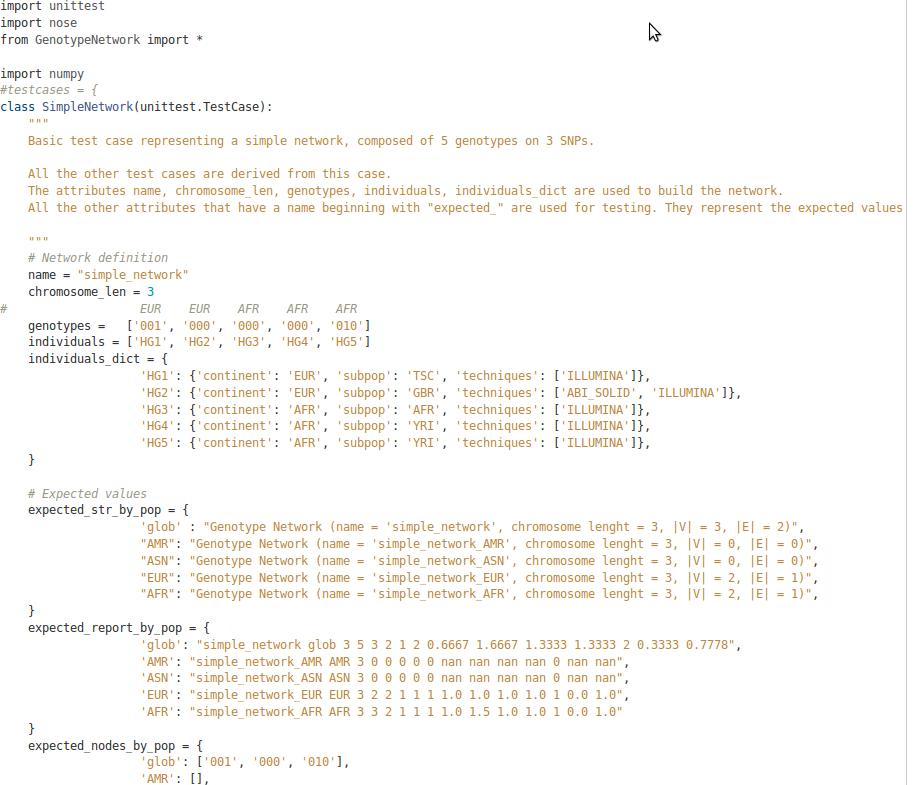
The only way to make sure that the script calculated the properties correctly was to manually calculate some examples, and compare the output. Check here an example of such test. Calculating things manually takes a lot of time and is a bit boring, but in some cases it is necessary. In effect, there are a few errors that I was able to find thanks to this manual tests.
– tests to check that the scripts run correctly. My workflow included a lot of data processing steps (filtering, conversion to another format, etc..). So, there are also many tests that just call a function with a given parameter, and make sure that the output is correct.
How did I run the tests? In my case, I ran then manually, making use of a great tool called nosetests. I wrote a Rakefile rule (see next section), and just ran “rake test” every morning, or every time I introduced major changes to the code. The output was a log message, listing all the tests that failed or that ran correctly.
Some friends told me that in the software industry, some people use bots to automatize the execution of tests. I have never had the time to try any bot, but it must be easy to configure.
Take Home Message 4: Tests are good. They allow you to check that the code runs correctly on any computer, and they give you flexibility over changing functions.
5. Keeping the list of commands in a Makefile
Another best practice in Bioinformatics is to keep a list of all the commands needed to produce each result file, using a software called Make. For more information, I recommend you to check the Software Carpentry documents, a real bible for bioinformaticians.
In my case, I wanted to try a tool similar to Make, called rake. I had read of rake in some discussion forums, and I was curious to try it. My final opionion on rake after using it is that it is better organized than make and that it has some advantages, but that it still misses some important features. The debugging is difficult, and I don’t understand why there is not an equivalent of the -n make option, to check the execution of a rule. Moreover, I still don’t like the way it handles multiple file names as prerequisites.
Click on the figure to see my full Rakefile:

This Rakefile contained a lot more of rules, but then I cleaned up a bit. You can also see the list of rules if you download the code, and type rake -T:

In a Rakefile, you basically have a list of rules, each one defining a set of bash calls. For example, you can have a rule to call run the python script you wrote to download the whole 1000 Genomes data from the FTP. As another example, you can have a rule to call the script to generate a plot from your data. If you are interested in learning more, you should really read the Software Carpentry pages.
In the end I am not 100% satisfied with rake. I had to run the scripts so many times, and try so many options, that the rules in the Rakefile were frequently outdated. I ended up writing the command line calls in the commit message (see the previous section on version control). I kept updating the Rakefile with the most important rules, but for the rest I relied on the commit message.
In any case, I think that the Rakefile will be useful to people wishing to reproduce my results. Thanks to the Rakefile, they will be able to see the commands needed to execute the most important tasks, and execute them. I guess that I am using Rake more for keeping documentation, than for actually executing the pipeline.
Take Home Message 5: make and Rakefiles can be used to keep a list of bash commands, and associate them with tasks to generate result files.
6. Keeping a board of To-Dos (Kanban/Scrum)
My daily work was organized as a KanBan board, which is simply a table with columns for Tasks to Do, Tasks Being Done, and Tasks Done. Click on the image to see my daily KanBan board:
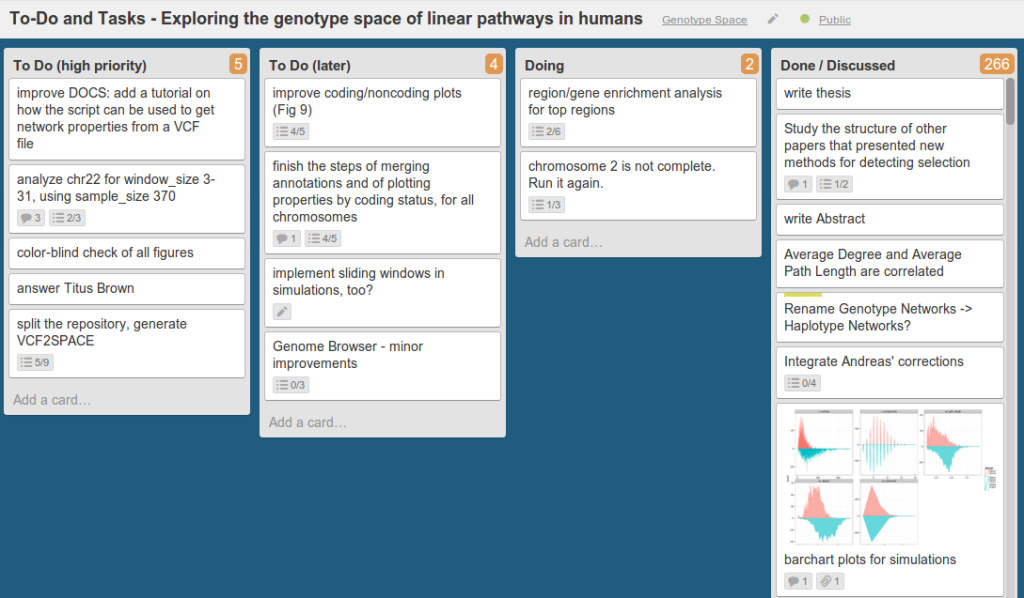
The KanBan board is a great Life Saver, and it has been the most useful tool I have used for this project. I am grateful to Joel Spolsky and his team for developing Trello (the software used to keep the board). Thanks, thanks, thanks.
In my KanBan board, I had four key columns: two for To Dos (divided into high and low priority), one for the tasks being done, and one for the tasks completed. There are other columns, but they are mostly notes.
Every day, the first thing that I would do was to open this KanBan board, and check which tasks were left from the previous days. At the end of every day, I looked at the board again, and moved the tasks that I had completed, or that I had postponed. Well, in reality I was a little less organized (checking the tasks at noon, and marking them as I finished them), but it was more or less like that.
The great advantage of a KanBan board is that you don’t forget many small tasks and ideas. If you have a new idea about a plot or an analysis, you can just write it down in the board, and then continue working on what you were doing before. I think that without this board, I would have forgot about 80 % of the ideas I had. I can not count the times when, thanks to the board, I realized that I was forgetting some important task.
One thing that I didn’t manage to do is to convince my colleague to use the board often. Unfortunately, they were too busy, and I was so deep into the project that it was difficult for them to follow all the single tasks. In any case, I think that if it is used from the beginning, the KanBan board is a great tool to manage a project.
Take Home Message 6: Keep a KanBan board, it will save you much time.
7. Gamestorming techniques to get feedback at a conference
This was mostly for fun, after attending a session of the local “Gamestorming” group in Barcelona.
In September 2012, when I was in the middle of the project, I presented a poster on it at the European Conference for Computational Biology (ECCB) in Basel. As a way to get more feedback on the poster, I’ve added a section at the bottom, where people could add feedback using post-its. See the figure below:

This initiative got a lot of success, and many people left me notes on it. I have recompiled all the feedback obtained this way in this trello board: ECCB feedback on the genotype space poster.
Take home message 7: use post-its to get feedback on a poster during a conference.
8. Putting the manuscript on ArXiv
The last “Best Practice” for this work has been to publish it on ArXiv, before sending it to a peer review journal.
I think that prepublishing in ArXiv is specially appropriate in the case of this work. This paper presents a new methodology, a new approach to the analysis of next generation sequencing data. To our knowledge, we believe that the method presented is new; however, we may have missed some literature, and the only way to be sure is to ask the opinion of other experts.
I hope that the people who follow ArXiv will give us some feedback on it – specially those from Haldane’s Sieve. Even negative comments will be welcome.

Take Home Message 8: ArXiv is a good way to get feedback on an article, specially if you are submitting something new.
Great list. Now lets see if I can implement any of them in my workflow ;) Thanks for sharing.
You did a great work! I want to steal some of your tricks in my projects too. :-) Also, only now I see that you were in Zurich exactly when I spent my 3-months stay at the ETH institute in Basel. I went to Zurich for some lab meetings, if I had known you were there I’d have come to say hello :-)
Excellent post. Too many come to bioinformatics with zero formal training (like myself). But as in everything there are one or two ‘right ways’ and many ‘wrong ways’ to get things done. And everyone benefits when one doesn’t need to re-invent the right ways. Thank you for sharing your right ways. My fave: gamestormed poster. Awesome.
Thank you to everybody for the comments :-) I am glad you liked the post.
I see you share interesting stuff here, you
can earn some extra money, your website has huge potential, for the monetizing method, just type
in google – K2 advices how to monetize a website
I read a lot of interesting articles here. Probably you spend
a lot of time writing, i know how to save you a lot of work, there is an online tool that creates unique, google friendly posts in seconds, just
search in google – laranitas free content source
You share interesting things here. I think that your website can go viral easily, but you must give it initial boost and i know
how to do it, just search in google for – wcnu traffic
increase
Thanks for the great blog,
Yeah, I am also using similar tools, I really like the feedly website, but couldn’t get my collaborators to use it.
I just want to mention other tools such as Evernote and “Simple Mind”.
I use Evernote to share my results with my suppervisor so he can see my progress and use the ipad “Simple Mind” application to draw a mind map of how my paper is organized or highlight the big parts of my projects to discuss with my supervisor.
that’s really interesting, thank you for sharing it! I tried Evernote in the past but in the end I could not get used to it. I will give it another try :-)
Hi,
Alert: Long message.
Thanks for this, I came in through a link from a Bionformatics course.
I would like to ask: for those who are logging more “traditionally” ie. paper.
I wonder if there is a way using more tactile resources, ie cards, plastic wallets, stickers even for upper level information.
I’ve a lap top (which is actually a netbook) so minimal storage, the same can be said for my paper work.
I keep a thread for complex data research without actually having everyday coding skills.
I tried some simple organisational software and HTML; however
I like best your idea of stopping every 30 mins to log process.
I don’t plan to learn any general software as I’m going into genomics and
will learn industry specific.
I would like to say thank you for posting.
JM.